The phrase "local-first" has become the default pitch for a new category of AI memory tools. Data stays on your machine, no cloud required, privacy preserved. That positioning is accurate, but it glosses over a question that matters more to most developers: how much local infrastructure do you have to run?
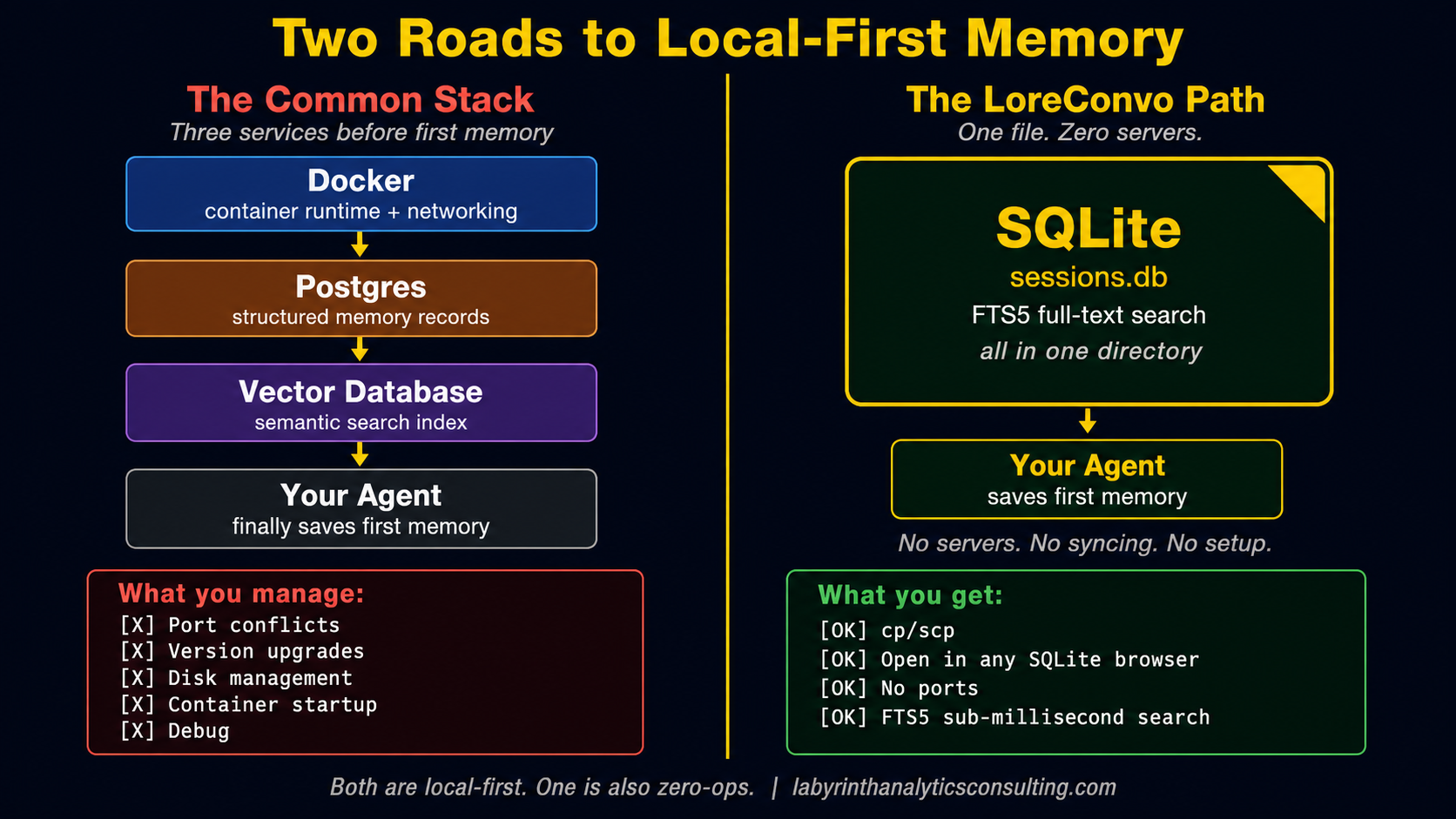
For some tools in this space, "local" means three services. Docker to manage the runtime, a relational database to store structured memory records, and a dedicated vector database to power semantic search. All three need to be installed, configured, and kept running. That is genuinely local -- your data never leaves the machine -- but it is not zero-ops. Before you save your first memory, you are debugging container networking.
LoreConvo takes a different position. Local data and zero infrastructure are compatible goals, and the way to achieve both is to choose storage that does not require a server.
What "Zero Infrastructure" Actually Means
SQLite is a single file. There is no server process to start, no port to configure, no container to manage. When LoreConvo saves a session, it opens a file on disk, writes a row, and closes it. When you search, it runs a query against that file. The FTS5 full-text search index is built into SQLite -- there is no separate search service.
That is the full infrastructure footprint: one file. You can back it up with cp. You can move it to a new machine with scp. You can open it in any SQLite browser to inspect what your agents are saving. If you delete it, everything is gone and nothing else is broken.
In contrast, a memory system built on top of a relational database plus a vector database inherits all of those systems' operational requirements. Version upgrades need to happen for both. Disk space needs to be managed for both. When a query is slow, you debug across two systems. The local-first privacy guarantee holds, but the complexity profile is closer to running a small data stack than to installing a command-line tool.
The Search Trade-Off
The argument for the heavier infrastructure stack is usually semantic search. A vector database can find memories based on meaning rather than exact keywords -- a query about "authentication problems" finds the session where you debugged OAuth even if that word does not appear in the session title.
That trade-off was more significant before hybrid search existed. LoreConvo's Pro tier now combines FTS5 keyword matching with LanceDB-powered semantic search, running locally without any external API or cloud embedding service. The embeddings are computed on-device using a lightweight model. A query about "authentication problems" now finds the OAuth debugging session in LoreConvo too -- with zero additional infrastructure, because LanceDB stores its index as a directory of files alongside the SQLite database.
The argument for running Docker plus two databases to get vector search is harder to make when a single-file setup provides the same capability.
What You Give Up
Honest comparison requires acknowledging the gap that still exists. A dedicated vector database scales to millions of records with sub-millisecond retrieval. For an agent that needs to search across a company-wide knowledge graph with hundreds of thousands of entries, a vector-native backend may be the right call. The engineering complexity is the cost; the scale is the benefit.
LoreConvo is designed for a different scope: the memory a developer or a small team of agents needs to work effectively across sessions. Thousands of saved sessions, not millions. A scope where "did we talk about this before?" and "what did we decide last week?" are the primary queries. At that scale, SQLite with FTS5 and local embeddings handles the job without requiring a second database.
The MCP Transport Question
There is a subtler difference worth noting for developers embedding memory into agentic workflows: how the MCP server communicates.
Tools that run as Docker containers or expose local HTTP services communicate with Claude over SSE or HTTP. That works, but it means binding a port, managing a process, and dealing with the occasional "connection refused" when the container has not finished starting. For developers who run multiple MCP tools, port conflicts become a real friction point.
LoreConvo uses stdio transport -- the MCP server runs as a subprocess, communicating over standard input and output. No ports. No containers. No startup race conditions. The server starts when Claude needs it and exits when the session ends.
Choosing the Right Tool
If you need semantic similarity search across a very large corpus of facts -- millions of memories, company-wide knowledge, multi-user shared context -- then a vector-native backend with dedicated infrastructure might be worth the operational investment. The stack exists for good reasons.
If you want memory that works in five minutes, stores everything in a file you can inspect and back up, runs hybrid keyword and semantic search locally, and adds zero new services to your environment, LoreConvo is the more direct path. Both approaches are genuinely local-first. They make different bets about what "simple" means for your workflow.
The developers who found their way to local-first memory tools in the first place were usually running away from cloud dependency. It is worth making sure the tool you choose to solve that problem does not create a new kind of dependency in the process.
LoreConvo is available on the Anthropic marketplace and installs with uvx loreconvo. Free tier includes full-text search across fifty sessions. Pro tier adds hybrid semantic search and unlimited sessions.
Find it at labyrinthanalyticsconsulting.com/tools.