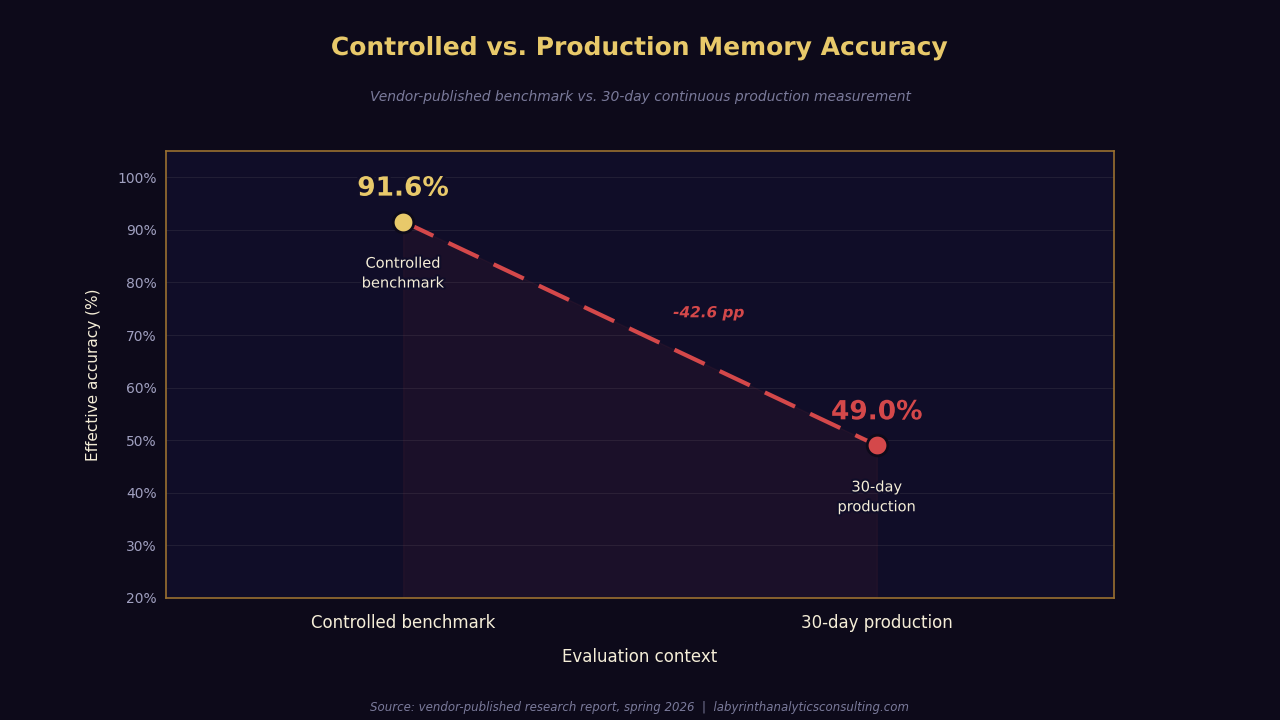
A major AI memory provider published their own research this spring measuring how well their system actually works in production. The controlled benchmark result was impressive: over ninety percent accuracy on standard evaluation corpora. The production result at thirty days was forty-nine percent.
That gap -- ninety-one to forty-nine -- is worth sitting with for a moment. The same system. The same vendor. The same definition of "working." The difference is what happens when the system runs continuously against real workloads instead of curated test sets.
This is not a vendor failing to disclose their results. They published the data themselves, in a public research report. That transparency is worth acknowledging. But the gap also tells you something important about what "AI agent memory" is actually solving -- and what it is not.
Why Auto-Capture Memory Degrades
The core challenge with automatic memory accumulation is that agents do not save discrete, well-structured facts. They save inferences, summaries, and working conclusions -- and those accumulate in ways that eventually contradict each other.
An agent that automatically captures "the user prefers short responses" at the beginning of a session, then captures "the user asked for a more detailed breakdown" three weeks later, ends up with two contradictory facts in its memory store. Neither is wrong in context. Both become noise when the system tries to answer "how should I structure my next response?"
At thirty days of continuous operation, a memory store built by automatic capture contains thousands of these contradictions. Facts about the same entity conflict. Preferences stated early have been reversed by subsequent behavior but the original entry was never expired. Working conclusions from resolved tasks still surface as if they were current state.
The controlled benchmark does not reveal this degradation because the test set is static. The evaluators know what the ground truth is and check against it. Production is dynamic -- ground truth shifts, context accumulates, and the memory system has no reliable way to expire stale entries without a human in the loop to say which facts are still valid.
What Explicit Saves Change
LoreConvo does not automatically extract memories from your conversation text. When a session ends, a hook fires and records the structured summary the agent or user has written -- decisions made, artifacts produced, questions left open. That record reflects what someone chose to commit, not what the model inferred from the raw exchange.
This is a different contract than automatic capture. The session-end hook automates the mechanics of saving, but the content is still explicitly structured. The things that get saved are the things someone decided were worth saving -- and put into words as decisions rather than leaving them as inferences the system tries to reconstruct later.
The result is a memory store that contains decisions, not inferences. Artifacts, not accumulations. Open questions that were explicitly flagged as open, not stale conclusions that were never closed out. When you search across saved sessions from the past month, you are searching a corpus of intentional records rather than a corpus of automatic accumulations.
LoreConvo does not make you immune to stale data. A decision saved three months ago may be obsolete by now, and LoreConvo has no way to know that on its own. The difference is that explicit saves put the staleness question in human hands. You decide what is worth keeping. You decide when a record is closed. The memory system stores what you give it and surfaces it when you ask.
The Professional Use Case
For agents operating in professional contexts -- engineering teams, data pipelines, consulting workflows -- the controlled-vs-production accuracy gap matters more than the headline benchmark. An agent that delivers ninety percent accuracy in evaluation but forty-nine percent in a month of real use is not reliable enough to trust with consequential context.
What those teams actually need is memory they can audit. Memory where they can see what the agent knows, correct a stale entry, and confirm that the correction took effect. Memory that does not silently accumulate contradictions across sessions.
Explicit saves and structured tagging are not features for users who enjoy manual data entry. They are features for users who need to be able to trust what their agents remember. The audit trail is the product.
The Benchmark Number Is Not the Lie
To be clear about what this data shows: the ninety-one percent controlled benchmark is not misleading. It accurately describes the system's performance on the evaluation task. The problem is what gets amplified in marketing copy versus what gets buried in the methodology section.
When a memory system is evaluated on a static test set with known ground truth, it looks like a different product than it is in continuous production. The evaluation is easier -- not because the vendor cheated, but because production is harder than any benchmark captures. Every memory system faces this gap to some degree. The question is how honestly it gets communicated and how much it matters for the specific workload.
For developers building agents that need to stay reliable over weeks and months, the thirty-day production number is the one that determines whether the system makes it into the stack.
LoreConvo stores what you structure and commit, surfaces what you search, and keeps your memory layer free of automatically-inferred contradictions. Free tier includes fifty sessions. Pro tier adds hybrid semantic search and unlimited sessions.
Find it at /tools.