Shipping fast beats perfect
We launched LoreConvo with SQLite's full-text search (FTS5) because it was fast, required zero external dependencies, and worked for exact-match retrieval. Three months of production data confirmed it was the right call.
It was also wrong for everything else.
The test
We gathered 217 real LoreConvo sessions (2026-03-22 through 2026-04-13) and built a test suite of 20 search queries representing actual user workflows. The queries fell into five categories:
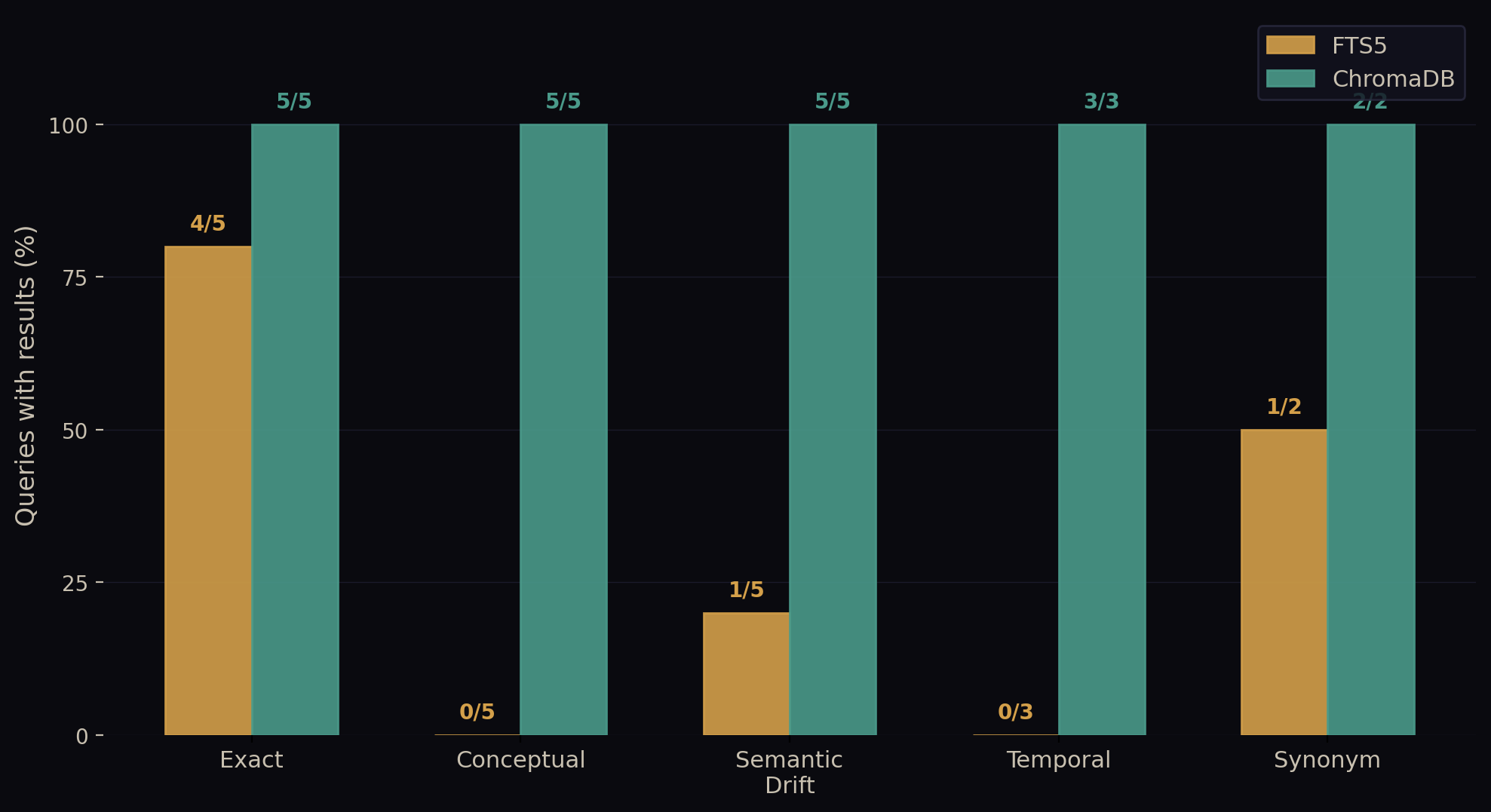
We started with exact matches: "safe_git.py", "BSL 1.1 license", "MEG-059", "K-1 parser", "Stripe billing integration". These are the kinds of searches where you remember the specific term you're looking for and just want the system to find it.
Then we tested conceptual queries: "how has the agent architecture evolved", "decisions about monetization strategy", "security vulnerabilities found and fixed", "what went wrong and needed debugging", "progress toward revenue goals". Here, the reader isn't remembering a specific phrase -- they're describing an idea or problem and hoping the search engine understands what they're after.
We included semantic drift: "persistent memory across conversations", "project knowledge base", "automated testing and quality checks", "protecting against supply chain attacks", "recurring scheduled automation". These queries use different words to express concepts that are well-documented in the corpus, testing whether the search engine can bridge the gap between how you ask and how you originally wrote it down.
Temporal queries checked whether the system understood time-based searches: "what changed last week", "earliest architecture decisions", "most impactful sessions this month". These require understanding both when something happened and what it meant.
Finally, we tested synonyms: "plugin marketplace distribution" and "database migration and renaming". The underlying work is documented extensively, but under different terminology.
We ran each query against our current FTS5 search engine and against ChromaDB as a standard vector-database baseline.
The results
FTS5 returned results on 6 out of 20 queries (30%). ChromaDB returned results on 20 out of 20 queries (100%).
FTS5 never uniquely found something ChromaDB missed.
Where FTS5 wins — and where it doesn't
FTS5 has genuine strengths. It's remarkably fast: 0.6ms average latency compared to 4.0ms for ChromaDB (6.7x faster). When it finds a match, it's exact -- zero false positives. The query logic is transparent and easy to debug. On exact-token searches, FTS5 hit on 4 out of 5 queries -- the miss was "K-1 parser", likely a hyphen tokenization edge case. When it works, it's safe, surgical, predictable.
The problem is that searching a labyrinth of your own thoughts by exact keyword only works if you remember the exact path you took the first time. Most of the time, you don't.
The system drew a complete blank on every conceptual query we threw at it (0 out of 5 hits). Ask "how has the agent architecture evolved" and FTS5 returns nothing, because no document uses that exact phrase. The underlying work is extensively documented -- just with different words. But FTS5 has no way to bridge the gap.
Time-based searches exposed the same limitation. "What changed last week" requires understanding both when something happened and what it meant. FTS5 failed on all three temporal queries because it has no awareness of dates or semantic similarity across time.
Synonym searches told a mixed story. FTS5 found "plugin marketplace distribution" (1/2) because enough of those tokens appear in the source documents. But "database migration and renaming" -- describing the LoreConvo rebrand work that's documented under completely different terms -- returned nothing. When your terminology happens to overlap with the original text, FTS5 works. When it doesn't, you get silence.
The cost of silence
A search that returns nothing doesn't feel like a failure — it feels like the information doesn't exist. But it does. The user has to abandon the search and re-read through old sessions manually. They have to re-explain context in the next conversation. They lose the advantage of having captured their thinking in the first place.
Over 217 sessions, FTS5's silence on conceptual queries (0/5 hits) means users lose access to entire categories of their own work — not because it's missing, but because they phrased the question differently than when they documented it.
ChromaDB's tradeoff
ChromaDB returned something for every query. That's appealing until you read the results. Low-similarity matches (confidence < 0.25) often have nothing to do with the query. We asked "progress toward revenue goals" and got a LinkedIn draft from a product roadmap session because both documents contain the word "progress" — but the context is completely different.
A production system can filter that noise with a confidence threshold. But then you're essentially choosing: either you get silence (like FTS5) or you accept wrong answers (like ChromaDB below 0.6 confidence).
What this means
Our v1 choice was correct: FTS5 + fast shipping = product market validation in 3 months.
The v2 data is also clear: we need hybrid search.
Keep FTS5 for exact-match recall (it's fast, zero dependencies, and perfect). Add a vector-similarity layer as a fallback when exact search returns nothing. Re-rank results by semantic relevance.
The roadmap
We're implementing hybrid search using FastEmbed, a local ONNX-based embedding library. This is a conscious choice of approach.
We could use a cloud vector database. It would work. But we'd be asking you to hand your session data to a third-party API on every search. FastEmbed runs locally. Your data never leaves your machine. The embedding inference is CPU-optimized by design, which aligns with our zero-external-dependencies model.
Our benchmark data showed we need approximately 0.6 similarity confidence to filter noise — above that threshold, ChromaDB's results became useful. FastEmbed gives us that recall with minimal latency impact. The overhead is acceptable for a search fallback.
This work is tracked in our architecture review and is currently in active development for an upcoming LoreConvo release.
Why we're telling you this
Because our business depends on you trusting us to make good calls with your data.
We benchmarked our own product against a known alternative and published the results. Our FTS5 engine is not sophisticated, and we said so. The data showed us exactly where to improve, so we will.
That's how builders think. We measure before we change.
If you want to see what LoreConvo does today — and where it's headed — check out our tools page.